I've been evaluating a ZFS-on-NBD based backup system for several weeks. I've now made a decision if I want to adopt this new setup, or stick with S3QL.
To make it short, I will drop my experiments with ZFS and continue using S3QL.
The main reasons for this are that the advantages of using ZFS are not as big as I had hoped, and that I discovered additional problems with the setup. But let me start with the positive things.
To recap: my final setup consisted of a ZFS pool spanning two bcache devices (one regular vdev, one special vdev). Each bcache device was backed by a loopback-mounted cache file and an NBD device. The NBD devices were backed by S3 buckets accessed through S3Backer running as an NBDkit plugin, one with a large object size and one with a small object size (for more details, refer to my previous post).
Having tested this for a few weeks, I found that:
- Backups, overall, ran fine and without issues.
- Hibernation/suspend and resume worked flawlessly even when the backup was running. By limiting the bandwidth of the rsync process, I was also able to prevent the bcache from filling, and thus able to suspend even when backing up more data that would fit into the cache.
- Performance of file system traversal was good enough for me not to notice it (in particular since it did not block suspend).
- Trim performance was not a concern either (though I used s3backer's --listBlocks flag).
However, several things did not pan out as I had hoped:
- The use of the special vdev for smaller writes did not work as expected: large amounts of data were still written to this device with large request sizes, resulting in needless write splitting (see below for details).
- Similarly, the regular vdev (backed by the bucket with larger object size) received a large numbers of small (4k) requests, resulting in needless write amplification.
- I realized that there is no way to invalidate the local bcache (short of manually deleting it). This means that when the bucket is mounted from different systems, data corruption will eventually result (because the contents of the cache no longer reflect what's actually stored in the bucket).
- At times, the setup script would fail with a No Such Device error when writing to /sys/block/{nbd_dev}/bcache/stop.
I have no doubts that at least the last two issues could be resolved in some way while keeping the overall setup mostly the same. However, I think this setup is already well past the point where it is more complex and fragile than using S3QL + FUSE - even if S3QL is out-of-tree and has a much smaller userbase. Combined with the increased traffic and latency due to the frequent mismatches between write request size and object size, I have therefore decided that this is not a route I want to pursue further.
Still, I feel like I've learned a lot along the way, and I certainly feel more confident in my use of S3QL again! I might even make another effort to finally found a solution for incremental uploads/downloads of the metadata database :-).
Appendix: Request Size Distribution
In the small object size bucket (4k), the vast majority of write requests had the expected 4k size:
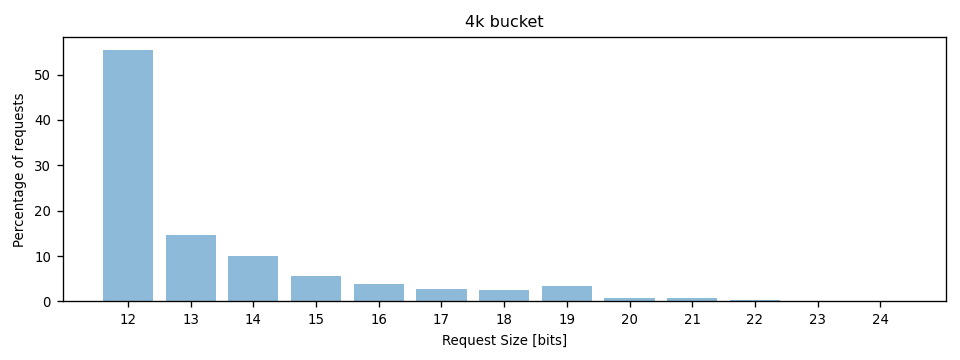
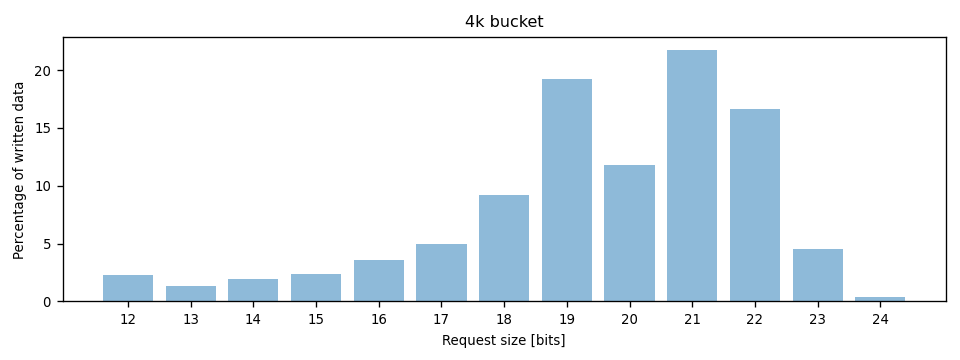
But when looking at the total amount of data that was written, less than 5% of it was written with 4k requests:
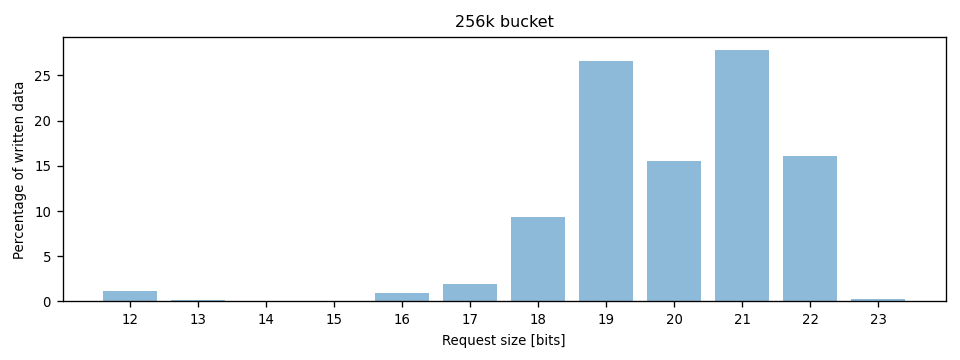
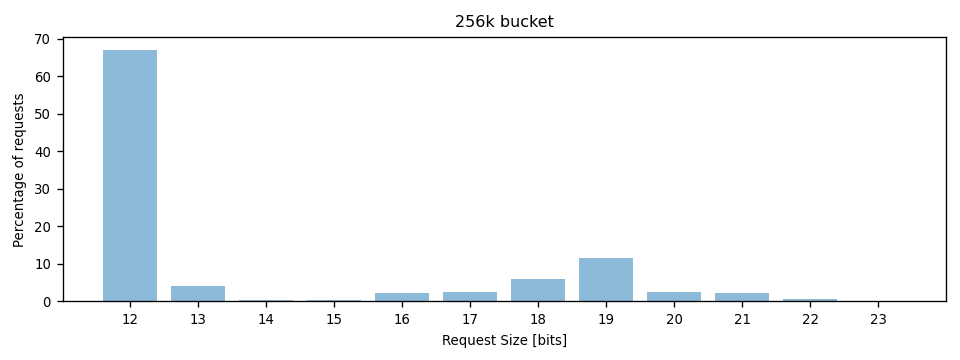
In the large object size bucket (256k), the percentage of large write requests was bigger than in the 4k bucket, but 4k writes were still the most common write request size:
But at least by volume, most of the data was written in larger requests: